Chapter 24 Tidymodels vs Scikit-learn
Scikit-learn, like tidymodels, is a framework to define machine learning models and train them.
As an open-source project, it has a large community of contributors and users. It is well-documented and has a wide range of algorithms and tools for data preprocessing, model selection, and evaluation. It is the de facto standard for machine learning in Python.
Even if models have no direct implementation in scikit-learn, the third-party libraries often implement the scikit-learn API, making them compatible with the framework. xgboost is a popular example for this.
There are many parallels between Tidymodels and scikit-learn; both have a similar approach to model definition and training. You will recognize many of the ideas and concepts from the tidymodels framework in scikit-learn.
Figure 24.1 shows the Python packages mapped onto the modeling workflow of Figure 6.1.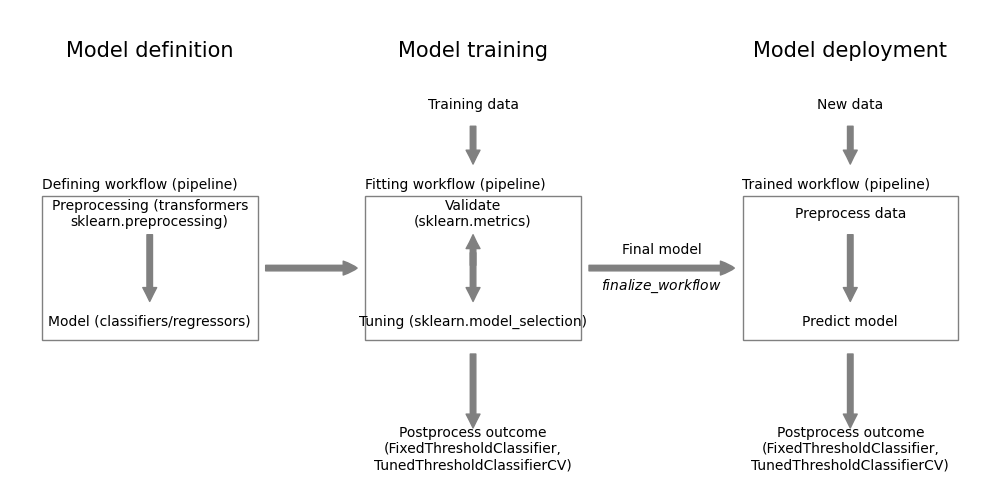
Figure 24.1: Modeling workflow
24.1 Load required packages
Like in R, we start with the import of the required packages:
Code
Python:
Code
import pandas as pd
import matplotlib.pyplot as plt
from sklearn import preprocessing
from sklearn.model_selection import (train_test_split, RandomizedSearchCV,
cross_val_predict)
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import Pipeline
from sklearn.linear_model import LogisticRegressionR:
24.2 Load the data
Code
data <- read_csv("https://gedeck.github.io/DS-6030/datasets/loan_prediction.csv",
show_col_types=FALSE) %>%
drop_na() %>%
mutate(
Gender=as.factor(Gender),
Married=as.factor(Married),
Dependents=gsub("\\+", "", Dependents) %>% as.numeric(),
Education=as.factor(Education),
Self_Employed=as.factor(Self_Employed),
Credit_History=as.factor(Credit_History),
Property_Area=as.factor(Property_Area),
Loan_Status=factor(Loan_Status, levels=c("N", "Y"), labels=c("No", "Yes"))
) %>%
select(-Loan_ID)Code
data = pd.read_csv("https://gedeck.github.io/DS-6030/datasets/loan_prediction.csv")
data = data.dropna()
data['Dependents'] = [int(str(s).strip('+')) for s in data['Dependents']]
data['Loan_Status'] = [1 if s == 'Y' else 0 for s in data['Loan_Status']]
outcome = 'Loan_Status'
predictors = ['Gender', 'Married', 'Dependents', 'Education', 'Self_Employed',
'ApplicantIncome', 'CoapplicantIncome', 'LoanAmount', 'Loan_Amount_Term',
'Credit_History', 'Property_Area']24.3 Split the data into training and holdout data
Split dataset into training and holdout data
Code
Code
## ((384, 11), (96, 11), (384,), (96,))24.4 Define the model
R:
Code
formula <- Loan_Status ~ Gender + Married + Dependents + Education + Self_Employed +
ApplicantIncome + CoapplicantIncome + LoanAmount + Loan_Amount_Term +
Credit_History + Property_Area
recipe_spec <- recipe(formula, data=train_data) %>%
step_dummy(all_nominal(), -all_outcomes())
# recipe_spec %>% prep() %>% bake(new_data=NULL) %>% head()
model_spec <- logistic_reg(engine="glmnet", mode="classification",
penalty=tune(), mixture=0)
wf <- workflow() %>%
add_model(model_spec) %>%
add_recipe(recipe_spec)Python:
Code
preprocess = ColumnTransformer([
('encoder', preprocessing.OneHotEncoder(drop='first'),
['Gender', 'Married', 'Education', 'Self_Employed', 'Property_Area']),
('unchanged', 'passthrough',
['Dependents', 'ApplicantIncome', 'CoapplicantIncome', 'LoanAmount',
'Loan_Amount_Term', 'Credit_History']),
])
# preprocess.fit_transform(data).round(4)[:20,]
model = Pipeline([
('preprocess', preprocess),
('classifier', LogisticRegression(penalty='l2', max_iter=10_000))
])24.5 Parameter tuning using cross-validation
Code
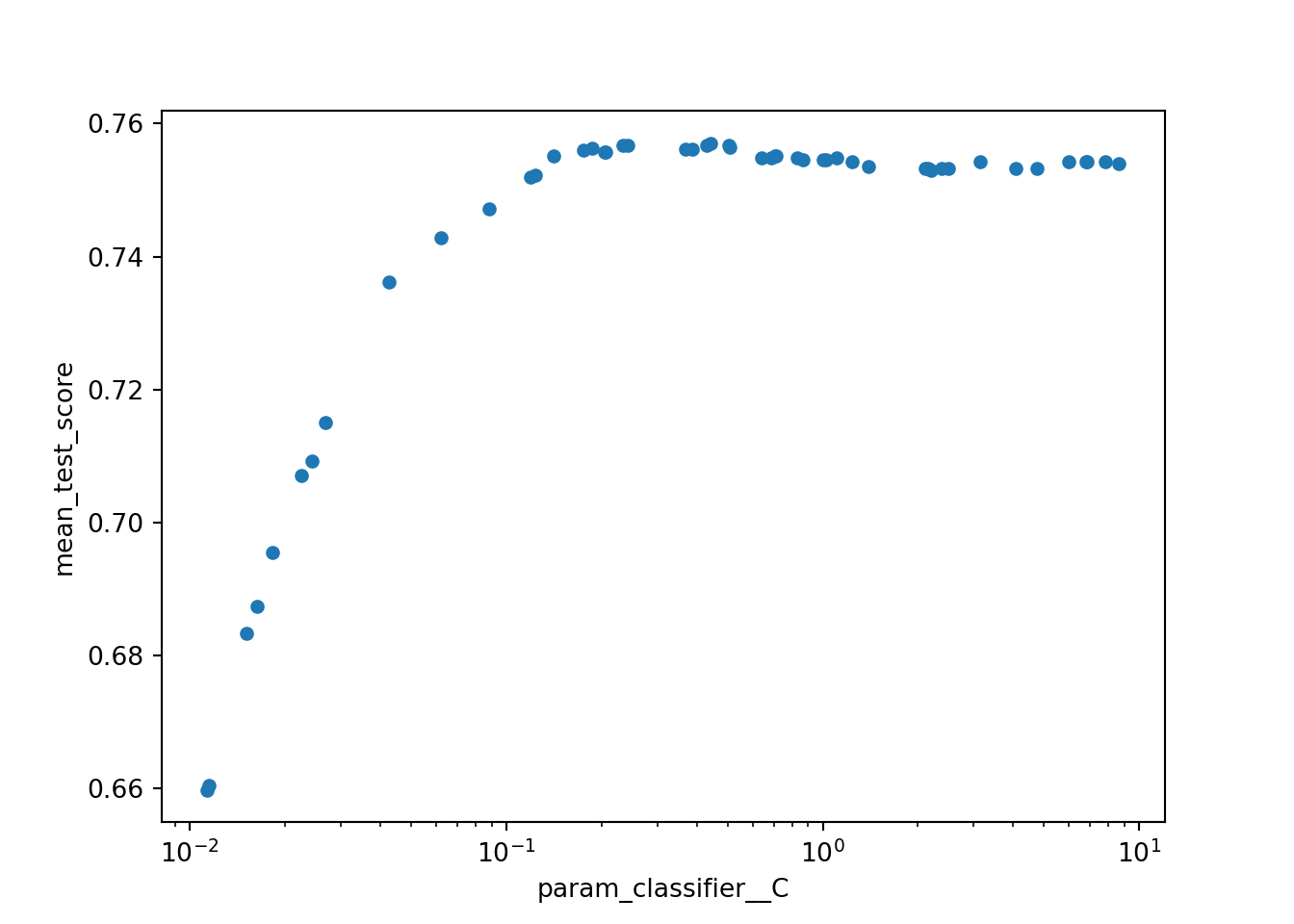
Tune the penalty hyperparameter using Bayesian hyperparameter optimization:
Code
## ! No improvement for 10 iterations; returning current results.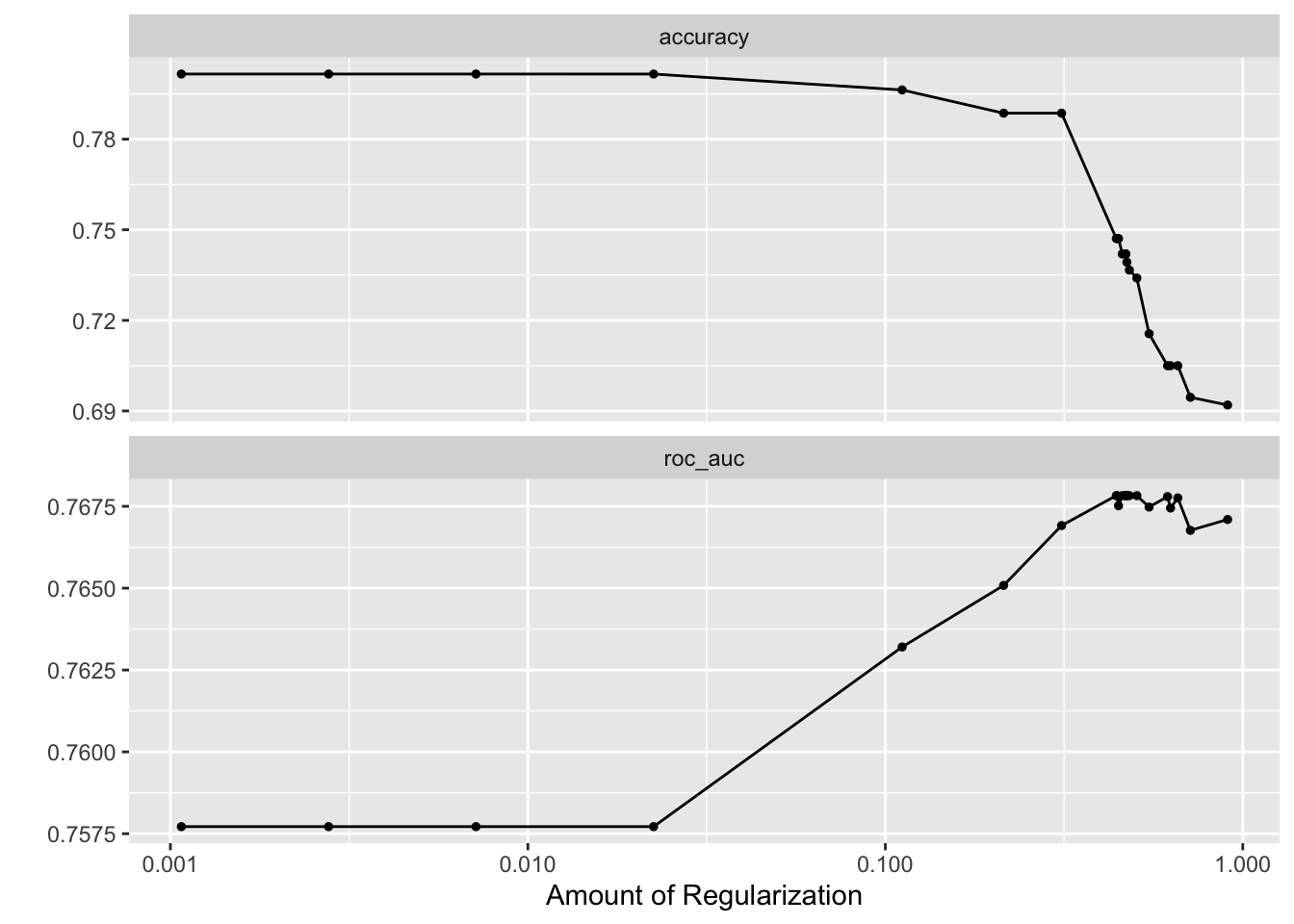
Figure 24.2: Autoplot shows the ROC-AUC for different values of the penalty hyperparameter.
Code
## (np.float64(0.7570491237157904), {'classifier__C': np.float64(0.44303752452182665)})Code
24.6 ROC curves
Code
best_parameter <- select_best(tune_wf, metric="roc_auc")
best_wf <- finalize_workflow(wf, best_parameter)
result_cv <- fit_resamples(best_wf, resamples,
metrics=cv_metrics, control=cv_control)
roc_cv_plot <- function(model_cv, model_name) {
cv_predictions <- collect_predictions(model_cv)
cv_roc <- cv_predictions %>% roc_curve(truth=Loan_Status, .pred_Yes, event_level="second")
autoplot(cv_roc) +
labs(title=model_name)
}
roc_cv_plot(result_cv, "Logistic regression")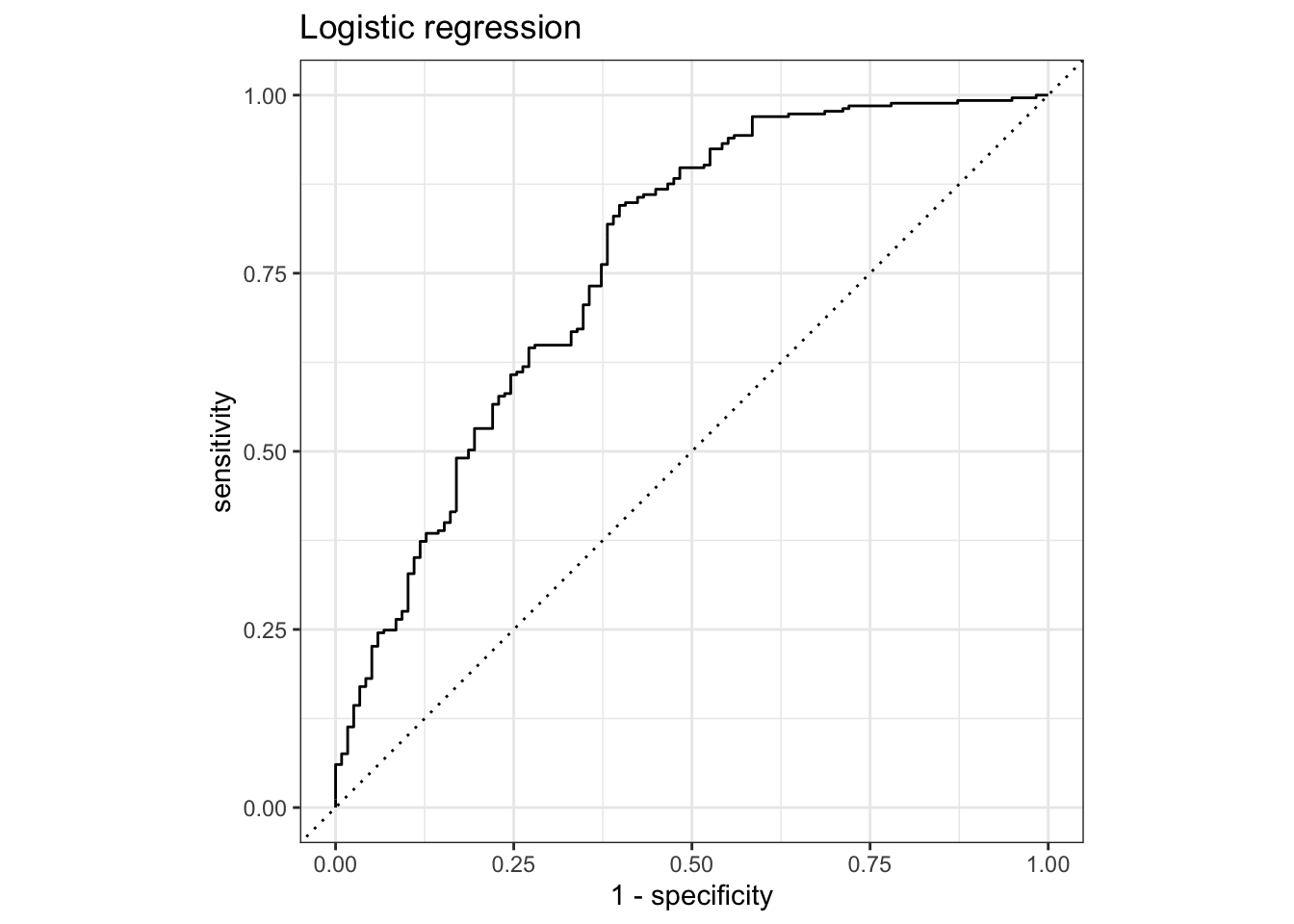
Code
from sklearn.metrics import roc_curve, auc
y_train_pred = cross_val_predict(search.best_estimator_, Xtrain, ytrain,
cv=10, method='predict_proba')
fpr, tpr, _ = roc_curve(ytrain, y_train_pred[:, 1])
roc_auc = auc(fpr, tpr)
fig, ax = plt.subplots(figsize=[5, 5])
_ = ax.plot(fpr, tpr, color='darkorange',
lw=2, label=f'ROC curve (area = {roc_auc:0.4f})')
_ = ax.plot([0, 1], [0, 1], color='navy', lw=2, linestyle='--')
_ = ax.set_xlim([0.0, 1.0])
_ = ax.set_ylim([0.0, 1.05])
_ = ax.set_xlabel('False Positive Rate (1 - Specificity)')
_ = ax.set_ylabel('True Positive Rate (Sensitivity)')
_ = ax.legend(loc="lower right")
_ = plt.show()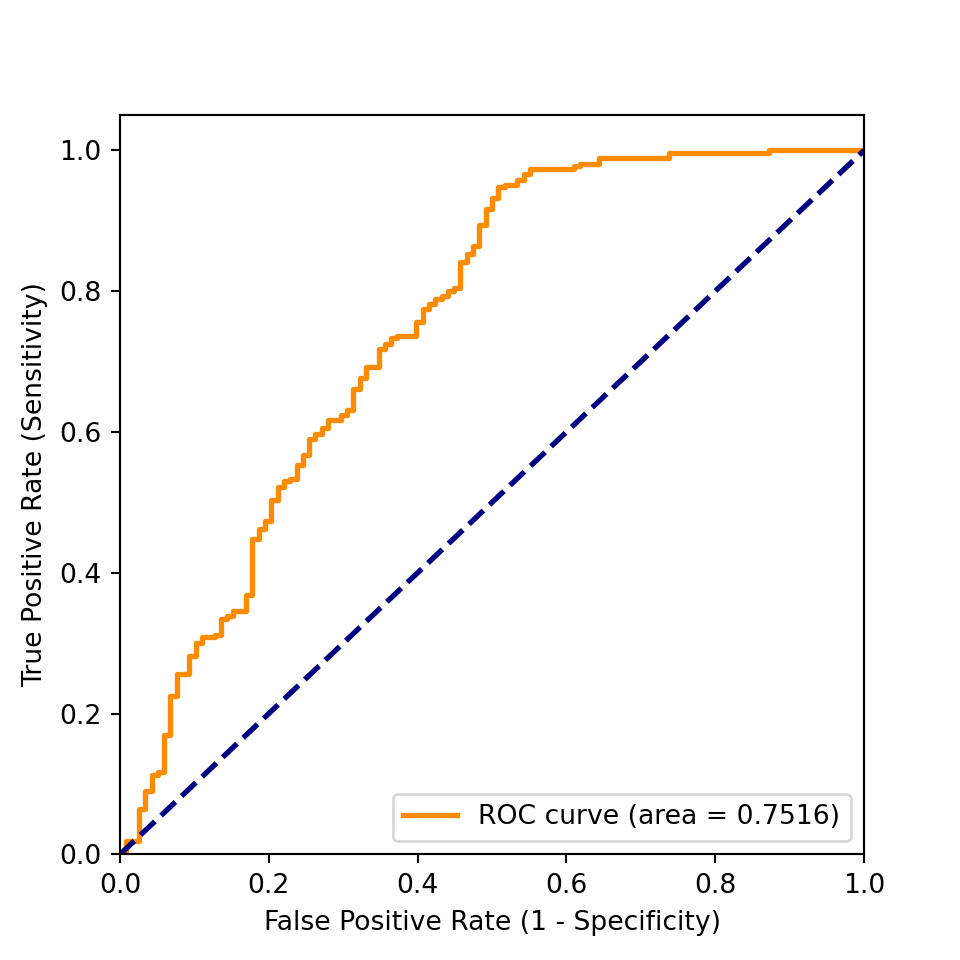
24.7 Finalize the workflow:
Code
The best roc_auc is obtained with a penalty of best_parameter['penalty'] = 0.4738658.
Use the tuned workflow for cross-validation and training the final model using the full dataset:
Code
Estimate model performance using the cross-validation results and the holdout data:
Code
cv_results <- collect_metrics(result_cv) %>%
select(.metric, mean) %>%
rename(.estimate=mean) %>%
mutate(result="Cross-validation")
holdout_predictions <- augment(fitted_model, new_data=holdout_data)
holdout_results <- bind_rows(
c(roc_auc(holdout_predictions, Loan_Status, .pred_Yes, event_level="second")),
c(accuracy(holdout_predictions, Loan_Status, .pred_class))
) %>%
select(-.estimator) %>%
mutate(result="Holdout")The performance metrics are summarized in the following table.
Code
| result | accuracy | roc_auc |
|---|---|---|
| Cross-validation | 0.739 | 0.768 |
| Holdout | 0.773 | 0.723 |
Python - By default, scikit_learn determines and returns the “best model” after cross-validation.
Code
from sklearn import metrics
best_model = search.best_estimator_
y_holdout_pred = best_model.predict(Xholdout)
pd.DataFrame({
'Accuracy': [
metrics.accuracy_score(ytrain, [1 if p > 0.5 else 0 for p in y_train_pred[:, 1]]),
metrics.accuracy_score(yholdout, y_holdout_pred)],
'ROC AUC': [
metrics.roc_auc_score(ytrain, y_train_pred[:, 1]),
metrics.roc_auc_score(yholdout, best_model.predict_proba(Xholdout)[:, 1])
],
}, index=['Cross-validation', 'Testset'])## Accuracy ROC AUC
## Cross-validation 0.809896 0.751593
## Testset 0.781250 0.715657