Errata
The errata list is a list of errors and their corrections that were found after the product was released. Use the Github issue tracker to submit new errors.
Chapter 1
- p. 12-13, code for Figure 1.7 and Figure 1.8 -
value_countscreates now column namedproportion:... X.loc[4, 'proportion'] = 0 # there are no samples with 4 blemishes add a row X = X.sort_index() # sort by number of blemishes ax = X['proportion'].plot.bar(color='grey', legend=False) ... X['Cumulative Frequency'] = X['proportion'].cumsum() ...
Chapter 2
- p. 55, Section 2.2.1.1 - Clarification: The
scipypackage uses the term probability mass function instead of probability distribution function for discrete distributions. Both terms are used in the literature. In Modern Statistics, we use the term probability distribution function for both discrete and continuous distributions.
Chapter 3
-
p. 162, Equation 3.30 - Replace percentile for the first $\chi^2$:
$\left(\frac{(n-1)S^2}{\chi^2{1-\alpha/2}[n-1]}, \frac{(n-1)S^2}{\chi^2{\alpha/2}[n-1]}\right)$
- p. 186, Figure 3.15 - Incorrect distribution used to create the Figure. The updated code creates the following Figure. The additional dashed lines show the approximated HPD.
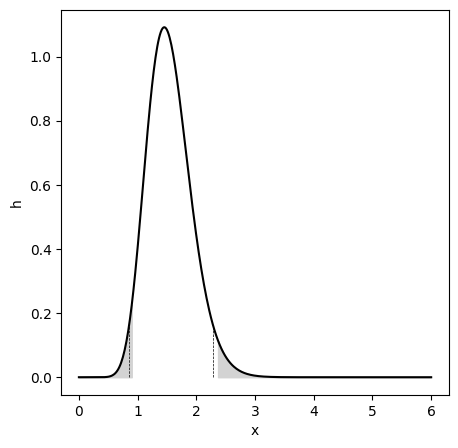
- p. 190 - Code sample, the
compute_bootcifunction cannot identifynp.meanas a function (see PR). Replace withB = pg.compute_bootci(etchrate, func=lambda x: np.mean(x), n_boot=1000, confidence=0.95, return_dist=True, seed=1) - p. 196 - Code sample, the print statement needs to contain f-strings. Replace
print('Xbar {Xbar:.2f} / SX {SX:.3f}') print('Ybar {Xbar:.2f} / SY {SX:.3f}')with
print(f'Xbar {Xbar:.2f} / SX {SX:.3f}') print(f'Ybar {Ybar:.2f} / SY {SY:.3f}')
Chapter 4
- p. 251:
Scalein the regression summary output corresponds to $S_e^2$.The $S_e^2$ value is shown in the regression summary output as
Scale. - Exercise 4.27: effects => affects
Chapter 6
- p. 333 - naming inconsistency of formula for polynomial model with seasonality. Replace
poly_formulawithformula:formula = 'Dow_Jones_Index ~ C(month) + I(trend**3) + I(trend**2) + trend + 1' model_3 = smf.ols(formula=formula, data=dow1941_df).fit() - p. 357 - Correct value of PMSE
The empirical PMSE is 0.8505.
Chapter 7
- p. 379 - iteritems deprecated in pandas package; code change required:
df = pd.DataFrame([ {satisfaction: counts for satisfaction, counts in response.value_counts().items()}, {satisfaction: counts for satisfaction, counts in response[q1_5].value_counts().items()}, ])
Chapter 8
- p. 400 - Import from
from skfda.preprocessing.dim_reduction.projectionis deprecated. Usefrom skfda.preprocessing.dim_reduction import FPCA - p. 404 - In equation 8.2, the matrix $V$ needs to be transposed:
$DTM \approx U * S * V’$ - p. 408 - estimating the network using HillClimbSearch now requires setting
max_indegreeto 1est = HillClimbSearch(data=abc) model = est.estimate(max_indegree=1, max_iter=int(1e4), show_progress=False, scoring_method='k2score')the updated code creates the following Figure 8.11 on p. 414
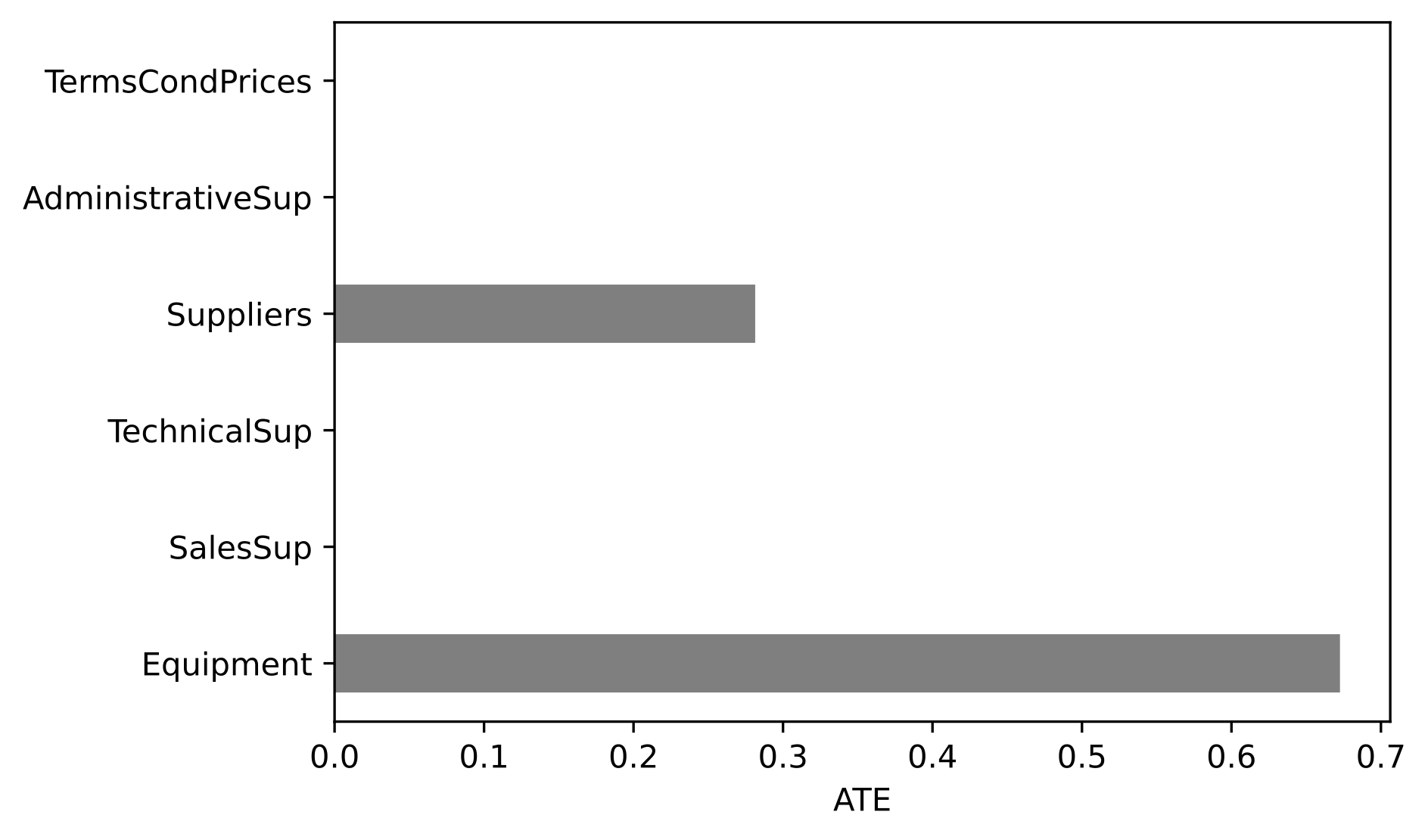 and requires adjustment of the text in Example 8.4
and requires adjustment of the text in Example 8.4We can see that changes to the Equipment and Suppliers have the largest ATE.
Index
- P-value, 152, 215